BK101
Knowledge Base
Human Search Engine
 Human Search Engine is a person or persons
searching for knowledge,
information or answers
on the internet, using
multiple search engines and
multiple resources and multiple websites, and using multiple keywords
and phrases in order to locate relevant information. A human search engine
may also use other media sources such as television, movies, documentaries,
radio, magazines, newspapers, advertisers, as well as recommendations
from other people. The main goal of a human
search engine is to find
relevant information and useful links to websites that pertain to a particular subject.
A human search engine is indexed by human
eyes and not by
algorithms.
Human Search Engine is a person or persons
searching for knowledge,
information or answers
on the internet, using
multiple search engines and
multiple resources and multiple websites, and using multiple keywords
and phrases in order to locate relevant information. A human search engine
may also use other media sources such as television, movies, documentaries,
radio, magazines, newspapers, advertisers, as well as recommendations
from other people. The main goal of a human
search engine is to find
relevant information and useful links to websites that pertain to a particular subject.
A human search engine is indexed by human
eyes and not by
algorithms. Internet Mining
is the application of data mining techniques that are used to discover
patterns
in the World Wide Web.
Web mining can be divided into three
different types. Web usage mining,
web content mining and web
structure
mining.
Internet Mining
is the application of data mining techniques that are used to discover
patterns
in the World Wide Web.
Web mining can be divided into three
different types. Web usage mining,
web content mining and web
structure
mining. Search Engine Types - Search Engine Flaws - Search Technology
Web Crawler is a meta-search engine that blends the top search results.
Web Robot is a software application that runs automated tasks or scripts over the Internet.
Aggregate is to form and gather separate units into a mass or whole.
Archivist is an information professional who assesses, collects, organizes, preserves, maintains control over, and provides access to records and archives determined to have long-term value.
Filtering - Defragging - Curation - Organizing Wiki Pages
Scribe is a person who serves as a professional copyist, especially one who made copies of manuscripts before the invention of automatic printing. The profession of the scribe, previously widespread across cultures, lost most of its prominence and status with the advent of the printing press. The work of scribes can involve copying manuscripts and other texts as well as secretarial and administrative duties such as the taking of dictation and keeping of business, judicial, and historical records for kings, nobles, temples, and cities. The profession has developed into public servants, journalists, accountants, bookkeepers, typists, and lawyers. In societies with low literacy rates, street-corner letter-writers (and readers) may still be found providing scribe service.
World Brain is a world encyclopedia that could help world citizens make the best use of universal information resources and make the best contribution to world peace.
Ontology is a knowledge domain that is usually hierarchical and contains all the relevant entities and their relations.
Ontology is the philosophical study of the nature of being, becoming, existence, or reality, as well as the basic categories of being and their relations.
Ontology in information science is a formal naming and definition of the types, properties, and interrelationships of the entities that really exist in a particular domain of discourse. Thus, it is basically a taxonomy.
Vannevar Bush envisioned the internet before modern computers were being used.
Mundaneum is a non profit organization based in Mons, Belgium that runs an exhibition space, website and archive which celebrate the legacy of the original Mundaneum established by Paul Otlet and Henri La Fontaine in the early twentieth century. Feltron.
I Am a Human Search Engine
I am a Human Search Engine, but I'm much more than that. I'm on a quest to understand the meaning of human intelligence. I'm also involved in the never ending process of finding ways to improve education, as well as understanding how the public is informed about the realities of our world and our current situation.
"The collector is the true resident of the interior. The collector dreams his way not only into a distant or bygone world, but also into a better one" - Walter Benjamin.
I'm an internet miner exploring the world wide web. I'm an archivist of information and knowledge. I'm extracting and aggregating the most valuable information and collecting the most informative websites that the internet and the world has to offer. I'm an information architect who is filtering and organizing the internet one website at a time. I'm a knowledge moderator, an internet scribe, and an intelligent agent, like Ai. But it's more than that. I'm an accumulator of knowledge who seeks to pass knowledge on to others. Lowering the entropy of the system since 2008.
Web Portal is a specially designed web site that brings information together from diverse sources in a uniform way.
Extract, Transform, Load is a process in database usage and especially in data warehousing that extracts data from homogeneous or heterogeneous data sources. Transforms the data for storing it in the proper format or structure for the purposes of querying and analysis. Loads it into the final target such as a database or operational data store, data mart, or data warehouse.
Welcome to my Journey in hyperlink heaven. Over 22 years of internet searches that are organized, categorized and contextualized. A researchers dream. I have already clicked my mouse over a 10 million times, and I've only just begun. I have tracked over 90% of my online activities since 1998, so my digital trail is a long one. This is my story about one mans journey through the Internet. What if you shared everything you learned? Did you ever wonder?
To put it simply I'm Organizing the Internet. Over the last 22 years since 1998, I have been surfing the world wide web, or trail blazing the internet, and curating my experience. I've asked the internet well over 500,000 Questions so far. And from those questions I have gathered a lot of Information, Knowledge and Resources. So I then organized this Information, Knowledge and Resources into categories. I then published it on my website so that the Information, Knowledge and Resources can be shared and used for educational purposes. I also share what I've personally learned from this incredible endless journey that I have taken through the internet. The internet is like the universe, I'm not over whelmed by the size of the internet, I'm just amazed from all the things that I have learned, and wondering just how much more will I be able to understand. Does knowledge and information have a limit? Well lets find out. Adventure for me has always been about discovering limits, this is just another adventure. I'm an internet surfer who has been riding the perfect wave for over 12 years. But this is nothing new. In the early 1900's, Paul Otlet pursued his quest to organize the world’s information.
A human search engine is someone who is not manipulated by money or manipulated by defective and ineffective algorithms. A human search engine is created by humans and is a service for humans. People want what's important. People want the most valuable knowledge and information that is available, without stupid adds, and without any ignorant manipulation or censorship. People want a trusted source for information, a source that cares about people more than money. We don't have everything, but who needs everything?
I'm a pilgrim on a pilgrimage. I'm an internet pathfinder whose task it is to carry out daily internet reconnaissance missions and document my findings. I'm not an internet guru or a gatekeeper, but I have created an excellent internet resource. Our physical journeys in the world are just as important as our mental explorations in the mind, the discoveries are endless. These days I seem to be leaving more digital footprints than actual footprints, which seems more meaningful in this day and age.
Quest is the act of searching for something, searching for an alternative that meets your needs. Quest is a difficult journey towards a goal, often symbolic, abstract in idea or metaphor. An adventure.
I'm more of a knowledge organizer and Knowledge Sharer than a knowledge keeper. I also wouldn't say that I'm a wisdom keeper, I am more of a wisdom sharer, which makes everyone a wisdom beneficiary.
I am just a bee in the hive of Knowledge, doing my part to keep the hive productive.
Beehive is an enclosed structure in which some honey bee species of the subgenus Apis live and raise their young.
Knowledge Hive - Knowledge Hives - The Hive Knowledge Platform (youtube)
Honeycomb is a mass of hexagonal prismatic wax cells built by honey bees in their nests to contain their larvae and stores of honey and pollen. Polyhedron.
“For every minute spent in organizing is an hour is earned.”
I feel like a human conduit, a passage, a pipe, a tunnel or a channel for transferring information and synchronizing information to and from various destinations.
Two Directory Projects are the work accumulated from one Human Editor - The Power of One (youtube)
Looking for Adventure.com has over 60,000 handpicked Websites. (External Links) - LFA took 14 years to accumulate as of 2016.
Basic Knowledge 101.com has over 50,000 handpicked Websites. (External Links) - Took 8 years to accumulate as of 2016.
The Internet and Computer Digital Information combined allows a person to save the work that they have done and create a living record of information and experiences. Example ' Looking for Adventure.com ' "not a total copy of my life but getting close". Things don't have to be written in stone anymore, but it doesn't hurt to have an extra copy.
When I started in 1998 I didn't know how much knowledge and information I would find, or did I know what kind of knowledge and information I would find, or did I know what kind of benefits would come from this knowledge and information. Like a miner in the olds days, you dig a little each day and see what you get. And wouldn't you know it, I hit the jackpot. The wealth of information and knowledge that there is in the world is enormous, and invaluable. But we can't celebrate just yet, we still need to distribute our wealth of knowledge and information and give everyone access. Other wise we will never fully benefit from our wealth of knowledge and information, or we will ever fully benefit from the enormous potential that it will give us.
"I saw a huge unexplored ocean, so naturally I dove in to take a look. 8 years later in 2016, I have been exploring this endless sea of knowledge, and have come to realize that I have found a home." About my Research.
What have I Learned about being a Human Search Engine
I am a semantic web as well as a Human Search Engine. Humans will always be better than machines when it comes to associations, perceptions, perspectives, categorizing and organizing, something's need to be done manually. Especially when it comes to organizing information and knowledge. Linking data, ontology learning, library and information science, creating a Visual Thesaurus and tag clouds is what I have been doing for 10 years. " Welcome to Web 3.0." I'm an intelligent agent combining logic and fuzzy logic, because there are just some things that machines or Artificial Intelligence cannot do or do well. Automated reasoning systems and computational logic can only do so much. So we need more intelligent humans than computer algorithms. Creating knowledge bases is absolutely essential. This is why I believe that having more Human Search Engines is a benefit to anyone seeking knowledge and information. Structuring websites into syntax link patterns and information into categories or taxonomies without being objective or impartial. Organizing information and websites so that visitors have an easy time finding what they're looking for, plus at the same time, showing them other things that are related to that particular subject that might also be of interest to them. More relevant choices and a great alternative and complement to search engines. But it's not easy to manage and maintain a human search engine, especially for one person. You're constantly updating the link data base, adding links, replacing links or removing some links altogether. Then on top of that there's the organizing and the adding of content, photos and video. And all the while your website grows and grows. Adding related subjects and subcategorizing information and links. Cross linking or cross-referencing so that related information can be found in more then one place while at the same time displaying more connections and more associations. Interconnectedness - Human Based Genetic Algorithms - Principle of Least Effort - Abstraction - Relational Model.
What being a Human Search Engine Represents
A Human Search Engine is more then just a website with hyperlinking, and it's more then just an Information hub or a node with contextual information and structured grouping. A Human Search Engine is also more than just knowledge organization, it's a branch of library and information science concerned with activities such as document description, indexing and classification performed in libraries, databases, archives, etc..
Intelligence Gathering is a method by which a country gathers information using non-governmental employees.
Internet Aggregation refers to a web site or computer software that aggregates a specific type of information from multiple online sources.
Knowledge Extraction is the creation of knowledge from structured relational databases or XML, and unstructured text, documents, images and sources. The resulting knowledge needs to be in a machine-readable and machine-interpretable format and must represent knowledge in a manner that facilitates inferencing.
Information Extraction - Information Filtering System
Glean is to extract information from various sources. Gather, as of natural products. Accumulate resources.
Database Indexing - File System - Knowledge Base - Knowledge Management
Media Curation - Digital Curation - Documentation
Master Directory is a file system cataloging structure which contains references to other computer files, and possibly other directories. On many computers, directories are known as folders, or drawers to provide some relevancy to a workbench or the traditional office file cabinet.
Web Directory is a directory on the World Wide Web. A collection of data organized into categories. It specializes in linking to other web sites and categorizing those links. Web of Knowledge.
Website Library - Types of Books
Web indexing refers to various methods for indexing the contents of a website or of the Internet as a whole. Individual websites or intranets may use a back-of-the-book index, while search engines usually use keywords and metadata to provide a more useful vocabulary for Internet or onsite searching. With the increase in the number of periodicals that have articles online, web indexing is also becoming important for periodical websites. Web Index.
Semantic Web is an extension of the Web through standards by the World Wide Web Consortium (W3C). The standards promote common data formats and exchange protocols on the Web, most fundamentally the Resource Description Framework (RDF). The Semantic Web provides a common framework that allows data to be shared and reused across application, enterprise, and community boundaries. The Semantic Web is therefore regarded as an integrator across different content, information applications and systems. The goal of the Semantic Web is to make Internet data machine-readable. Semantic Web Info.
Machine-Readable Data is data in a format that can be processed by a computer. Machine-readable data must be structured data and in a format that can be easily processed by a computer without human intervention while ensuring no semantic meaning is lost. Machine readable is not synonymous with digitally accessible. A digitally accessible document may be online, making it easier for humans to access via computers, but its content is much harder to extract, transform, and process via computer programming logic if it is not machine-readable. Extensible Markup Language (XML) is designed to be both human- and machine-readable, and Extensible Style Sheet Language Transformation (XSLT) is used to improve presentation of the data for human readability. For example, XSLT can be used to automatically render XML in Portable Document Format (PDF). Machine-readable data can be automatically transformed for human-readability but, generally speaking, the reverse is not true.
Academics - My Fundamental Contribution
In a way my work as a Human Search Engine is my dissertation. My thesis is Basic Knowledge 101 and proving the importance of a Human Operating System in regards to having a more comprehensive and effective education. This is my tenure. My Education Knowledge Database Project. This is just the beginning of my intellectual works. Basic Knowledge 101.com is my curriculum vitae. Working on this project I went from an undergraduate study, through postgraduate education right into a graduate program. I started out as a non-degree seeking student but I ended up with a master's degree and a doctoral degree, well almost. I have done my fieldwork, I have acquired specialized skills, I have done advanced original research. But I still have no name for my Advanced Academic Degree. Maybe "Internet Comprehension 101". My Business Card - HyperLand (youtube)
Academic Tenure is defending the principle of academic freedom, which holds that it is beneficial for society in the long run if scholars are free to hold and examine a variety of views. Tenure is to give someone a permanent post, especially as a teacher or professor.
Internet Studies is an interdisciplinary field studying the social, psychological, pedagogical, political, technical, cultural, artistic, and other dimensions of the Internet and associated information and communication technologies. Internet and society is a research field that addresses the interrelationship of Internet and society, i.e. how society has changed the Internet and how the Internet has changed society. Information Science - Peer-to-Peer - Open Source - Free Open Access.
How Can One Person Create Databases this Large in Such a Short Time
The techniques and methods are quite simple when you're using the Internet. You literally have thousands upon thousands of smart people indirectly doing a tremendous amount of work for you. This gives individuals the power and the ability to solve almost any problem. Sharing information and knowledge on a platform that millions of people can have access to has transformed our existence in so many ways that people cannot even comprehend the changes that are happening now or have happened already and will most likely happen in the future.
First Step: When doing internet searches, for what ever reason, you are bound to come across a website or keyword phrase that relates to your subject matter. Then you do more searches using those keywords and then save those keywords and websites to your database. This is very important because most likely you will never come across the same info related to those particular search parameters, so saving and documenting your findings is very important. Terminology Extraction.
Second Step: When reading, watching TV, watching a movie or even talking with someone, you are bound to come across ideas and keywords that you could use when searching for more information pertaining to your subject. Then again saving and documenting your findings is very important. It's always a good idea to have a pen and paper handy to write things down or you can use your cell phone to record a voice memo so that you don't forget your information or ideas. The main thing is to have a subject that you're interested in and at the same time being aware of what information is valuable to your subject when it finally presents itself. Combining a human algorithm with a randomized algorithm.
Third Step: Organizing, updating and improving your database so that it stays functional and easy to access. So my time is usually balanced between these three tasks, and yes it is time consuming. You can also use the Big 6 Techniques when gathering Information to help with your efficiency and effectiveness. I also created a Internet Searching Tips help Section for useful ideas. Glossary.
One Last Thing: If you spend a lot of time on the internet doing searches and looking for answers you are bound to come across some really useful websites and information that were not relevant to what you were originally searching for. So it's a good idea to start saving these useful websites in new categories or just save them in a appropriate named folder in your documents. This way you can share these websites with friends or just use them at some later time. It is sometimes called Creating Search Trails, which I have 21 years worth as of 2019. Not bad for a Personal Web Page.
Visible Web - World Wide Web - Dark Web
 I have always used the world wide
web or the surface web for my work. And I have always had a good
connection, but not a totally secure
connection. So just in case you need to search the web when the main
stream web becomes too risky, you should now about your alternatives.
I have always used the world wide
web or the surface web for my work. And I have always had a good
connection, but not a totally secure
connection. So just in case you need to search the web when the main
stream web becomes too risky, you should now about your alternatives.
World Wide Web is an information space of networked computers where documents and other web resources are identified by Uniform Resource Locators interlinked by hypertext links, and can be accessed via the Internet. URL is a website address.
Surface Web is that portion of the World Wide Web that is readily available to the general public and searchable with standard web search engines. It is the opposite of the deep web. The surface web is also called the Visible Web, Clearnet, Indexed Web, Indexable Web or Lightnet.
The Deep Web consists of those pages that Google and other search engines don't index. The Deep Web is about 500 times larger than the Visible Web, but the Visible Web is much easier to access. Deep Web (wiki).
The Dark Web is an actively hidden, often anonymous part of the deep web but it isn't inherently bad. Dark Internet (wiki).
Deep Web Exploring the Dark Internet, the part of the internet that very little people have ever seen. Memex (wiki).
How the Mysterious Dark Net is going Mainstream (video) - Tor Project.
Google has indexed 1 trillion pages so far in 2016, but that is only 5% of the total knowledge and information that we have.
Filtering - Gatekeeping
Information Filtering System is a system that removes redundant or unwanted information from an information stream, using semi automated or computerized methods prior to presentation to a human user. Its main goal is the management of any information overload, propaganda or errors, and the signal-to-noise ratio. To do this the user's profile is compared to some reference characteristics. These characteristics may originate from the information item using a the content-based approach, or from the user's social environment using the collaborative filtering approach. Filtering should never create a filter bubble that influences biases or blind conformity. Filtering is not to be confused with censorship. A filter is not a wall. Filtering is like speed reading. Retrieving the most essential information efficiently as possible.
Ratings - Free Speech Abuses - Social Network Monitoring
Filter is a device that removes something from whatever passes through it. A porous device for removing impurities or solid particles from a liquid or gas passed through it. Porous is something full of pores or vessels or holes allowing passage in and out.
Membranes - Polarizers
Collaborative Filtering is a technique used by recommender systems. Collaborative filtering has two senses, a narrow one and a more general one.
Relative - Tuning Out Irrelevant Information - Error Correcting
Data Cleansing is the process of detecting and correcting or removing corrupt or inaccurate records from a record set, table, or database and refers to identifying incomplete, incorrect, inaccurate or irrelevant parts of the data and then replacing, modifying, or deleting the dirty or coarse data. Data cleansing may be performed interactively with data wrangling tools, or as batch processing through scripting.
Gatekeeping is the process through which information is filtered for dissemination, whether for publication, broadcasting, the Internet, or some other mode of communication.
Gatekeeping in communication is the process through which information is filtered for dissemination, whether for publication, broadcasting, the Internet, or some other mode of communication. The academic theory of gatekeeping is founded in multiple fields of study, including communication studies, journalism, political science, and sociology. It was originally focused on the mass media with its few-to-many dynamic but now gatekeeping theory also addresses face-to-face communication and the many-to-many dynamic inherent in the Internet. The theory was first instituted by social psychologist Kurt Lewin in 1943. Gatekeeping occurs at all levels of the media structure—from a reporter deciding which sources are chosen to include in a story to editors deciding which stories are printed or covered, and includes media outlet owners and even advertisers. Wisdom Keeper.
Logic Gate - And, Or, Not. (algorithm filters) - Questioning
Gatekeeper are individuals who decide whether a given message will be distributed by a mass medium. Serve in various roles including academic admissions, financial advising, and news editing. Not to be confused with Mass Media.
Collaborative Filtering is the process of filtering for information or patterns using techniques involving collaboration among multiple agents, viewpoints, data sources, etc. Sometimes making automatic predictions about the interests of a user by collecting preferences or taste information from many users (collaborating).
Process of Elimination is a quick way of finding an answer to a problem by excluding low probability answers so that you can focus on the most probable answers. With multiple choices you can remove choices that are known to be incorrect so that your chances of getting the correct answer are greater. It is a logical method to identify an entity of interest among several ones by excluding all other entities. In educational testing, the process of elimination is a process of deleting options whereby the possibility of an option being correct is close to zero or significantly lower compared to other options. This version of the process does not guarantee success, even if only 1 option remains since it eliminates possibilities merely as improbable.
Reason by Deduction - Simplifying - Data Conversion
Filter in signal processing is a device or process that removes some unwanted components or features from a signal. Filtering is a class of signal processing, the defining feature of filters being the complete or partial suppression of some aspect of the signal. Noise.
Media Literacy - Sensors - Social Network Blocking
Abstraction is the act of withdrawing or removing something. A general concept formed by extracting common features from specific examples. The process of formulating general concepts by abstracting common properties of instances. A concept or idea not associated with any specific instance. Preoccupation with something to the exclusion of all else. Abstraction is a conceptual process by which general rules and concepts are derived from the usage and classification of specific examples. Conceptual abstractions may be formed by filtering the information content of a concept or an observable phenomenon, selecting only the aspects which are relevant for a particular purpose.
Extracting is to reason by deduction a principle or construe or make sense of a meaning. Extracting in chemistry is to purify or isolate using distillation. Obtain from and separate a substance, as by mechanical action. Extracting in mathematics is to calculate the root of a number. Extraction (information).
Extract, Transform, Load is the general procedure of copying data from one or more sources into a destination system which represents the data differently from the source(s) or in a different context than the source(s).
Data Migration is the process of selecting, preparing, extracting, and transforming data and permanently transferring it from one computer storage system to another.
Terminology Extraction is a subtask of information extraction. The goal of terminology extraction is to automatically extract relevant terms from a given corpus. Collect a vocabulary of domain-relevant terms, constituting the linguistic surface manifestation of domain concepts.
Data Cleansing is the process of detecting and correcting (or removing) corrupt or inaccurate records from a record set, table, or database and refers to identifying incomplete, incorrect, inaccurate or irrelevant parts of the data and then replacing, modifying, or deleting the dirty or coarse data. Data cleansing may be performed interactively with data wrangling tools, or as batch processing through scripting.
Data Scraping is a technique in which a computer program extracts data from human-readable output coming from another program. Information Extraction.
Web Scraping is data scraping used for extracting data from websites sometimes using a web crawler.
Screen Scraping is the process of collecting screen display data from one application and translating it so that another application can display it. This is normally done to capture data from a legacy application in order to display it using a more modern user interface.
Data Editing is defined as the process involving the review and adjustment of collected survey data. The purpose is to control the quality of the collected data. Data editing can be performed manually, with the assistance of a computer or a combination of both.
Data Wrangling is the process of transforming and mapping data from one "raw" data form into another format with the intent of making it more appropriate and valuable for a variety of downstream purposes such as analytics. A data wrangler is a person who performs these transformation operations. This may include further munging, data visualization, data aggregation, training a statistical model, as well as many other potential uses. Data munging as a process typically follows a set of general steps which begin with extracting the data in a raw form from the data source, "munging" the raw data using algorithms (e.g. sorting) or parsing the data into predefined data structures, and finally depositing the resulting content into a data sink for storage and future use.
Noisy Text Analytics is a process of information extraction whose goal is to automatically extract structured or semistructured information from noisy unstructured text data.
Fragmented - Deconstructed
Noisy Text noise can be seen as all the differences between the surface form of a coded representation of the text and the intended, correct, or original text.
Deep Packet Inspection is a form of computer network packet filtering that examines the data part (and possibly also the header) of a packet as it passes an inspection point, searching for protocol non-compliance, viruses, spam, intrusions, or defined criteria to decide whether the packet may pass or if it needs to be routed to a different destination, or, for the purpose of collecting statistical information that functions at the Application layer of the OSI (Open Systems Interconnection model).
Focus - Attention - Multi-Tasking
Filtering information is not bad, as long as you are filtering correctly and focused on a particular goal so that only relative information needs to be analyzed. The big problem is that people block relative information and then they naively call it filtering, which it is not. Most people are not aware that they are blocking relative information, or are they aware that they have biases against certain information. So the main difficulty is that people don't have enough knowledge and information in order to filter information without blocking relative information or important information. The process of information extraction needs to be learned and then practiced, and also verified in order to make sure that the process is effective and efficient. Eventually misinformation would be totally eliminated from the media because it could never get through the millions of people who are knowledgeable enough to quickly identify false information and then remove it and also stop the source from transmitting. Millions of filters will be working together to keep information accurate, that is the future. Filtering is a normal human process, it's just when you filter things, what things you are filtering, and why you filter things that makes all the difference. Watch Dogs.
The Information Age
We are now living in the Information Age. A time where information and knowledge is so abundant that we can no longer ignore it. But sadly, not everyone understands what information is, or understands the potential information, or has access to information. The Information age is the greatest transition of the human race, and of our planet. The power of knowledge is just beginning to be realized. Knowledge and information gives us an incredible ability to explore ourselves, and explore our world and our universe in ways that we have never imagined. Knowledge and information can improve the lives of every man, women and child on this planet. Knowledge and information will also help us understand the importance of all life forms on this planet like never before. This is truly the greatest awakening of our world.
Preserving Information - Information Economy - Knowledge Economy - Knowledge Market - Knowledge Management - Information Literacy - Information Stations - Information Overload.
Knowledge Open to the Public
Libre Knowledge knowledge released in such a way that users are free to read, listen to, watch, or otherwise experience it; to learn from or with it; to copy, adapt and use it for any purpose; and to share the work (unchanged or modified).
Knowledge Commons refers to information, data, and content that is collectively owned and managed by a community of users, particularly over the Internet. What distinguishes a knowledge commons from a commons of shared physical resources is that digital resources are non-subtractible; that is, multiple users can access the same digital resources with no effect on their quantity or quality.
Open Science - Open Source Education - Internet
Open Knowledge is knowledge that one is free to use, reuse, and redistribute without legal, social or technological restriction. Open knowledge is a set of principles and methodologies related to the production and distribution of knowledge works in an open manner. Knowledge is interpreted broadly to include data, content and general information.
Open Knowledge Initiative is an organization responsible for the specification of software interfaces comprising a Service Oriented Architecture (SOA) based on high level service definitions.
Open Access Publishing refers to online research outputs that are free of all restrictions on access (e.g. access tolls) and free of many restrictions on use (e.g. certain copyright and license restrictions)
Open Data is the idea that some data should be freely available to everyone to use and republish as they wish, without restrictions from copyright, patents or other mechanisms of control.
Open Content describes a creative work that others can copy or modify.
A Human Search Engine is a lot of work. I have been working an average of 20 Hours a week since 1998 and over 50 Hours a week since 2006. With over a Billion Websites containing over 450 billion web pages on the World Wide Web, there's a lot of information to be organized. And with almost 2 billion people on the internet there's a lot of minds to collaborate with. My Human Search Engine Design Methods are always improving, but I'm definitely not a professional Website Architecture so there is always more to learn. I'm constantly Multitasking so I do make mistakes from time to time, especially with proof reading my own writing, which seems almost impossible (Writers Blindness). This is why writers and authors have proof readers and copy editors, which is something I cannot afford right now, so please excuse me for my spelling errors and poor grammar. Besides that I'm still making progress and I'm always acquiring new knowledge, which always makes these projects fascinating and never boring. The Adventures in Learning You can also look at my website as web Indexing.
Web indexing means creating indexes for individual Web sites, intranets, collections of HTML documents, or even collections of Web sites. Web-indexing.org
Indexes are systematically arranged items, such as topics or names, that serve as entry points to go directly to desired information within a larger document or set of documents. Indexes are traditionally alphabetically arranged. But they may also make use of Hierarchical Arrangements, as provided by thesauri, or they may be entirely hierarchical, as in the case of taxonomies. An index might not even be displayed, if it incorporated into a searchable database.
Indexing is an analytic process of determining which concepts are worth indexing, what entry labels to use, and how to arrange the entries. As such, Web indexing is best done by individuals skilled in the craft of indexing, either through formal training or through self-taught reading and study.
Indexing is a list of words or phrases ('headings') and associated pointers ('locators') to where useful material relating to that heading can be found in a document or collection of documents. Examples are an index in the back matter of a book and an index that serves as a library catalog.
A Web index is often a browsable list of entries from which the user makes selections, but it may be non-displayed and searched by the user typing into a search box. A site A-Z index is a kind of Web index that resembles an alphabetical back-of-the-book style index, where the index entries are hyperlinked directly to the appropriate Web page or page section, rather than using page numbers.
Interwiki Links is a facility for creating links to the many wikis on the World Wide Web. Users avoid pasting in entire URLs (as they would for regular web pages) and instead use a shorthand similar to links within the same wiki (intrawiki links).
I'm like an isle in the internet library. Organizing data out of necessity while making it a value to others at the same time. Eventually connecting to other human search engines around the world to expand its reach and capabilities.
I like to describe my website as being kind of like a lateral Blog then the usual Linear Blog because I update multiple pages at once instead of just one. As of 2010 around 120,000 new weblogs are being created worldwide each day, but of the 70 million weblogs that have been created only around 15.5 million are actually active. Though blogs and User-Generated Content are useful to some extent I feel that too much time and effort is wasted, especially if the information and knowledge that is gained from a blog is not organized and categorized in a way that readers can utilize and access these archives like they would do with newspapers. This way someone can build knowledge based evidence and facts to use against corruption and incompetence. This would probably take a Central Location for all the blogs to submit too. This way useful knowledge and information is not lost in a sea of confusion. This is one of the reasons why this websites information and links will continue to be organized and updated so that the website continues to improve.
"Links in a Chain"
"There's a lot you don't know, welcome to web 3.0" This is not just my version of the internet, this is my vision of the internet. And this is not philosophy, it's just the best idea that I have so far until I can find something better to add to it, or replace it, or change it. A Think Tank who's only major influence is Logic.
"When an old man dies, it's like entire library burning down to the ground. But not for me, I'll just back it up on the internet."
Search Engines
 Organic Search Engine is a search engine that uses human
participation to filter the search results and assist users in clarifying
their search request. The goal is to provide users with a limited number
of relevant results, as opposed to traditional search engines that often
return a large number of results that may or may not be relevant.
Organic Search Engine is a search engine that uses human
participation to filter the search results and assist users in clarifying
their search request. The goal is to provide users with a limited number
of relevant results, as opposed to traditional search engines that often
return a large number of results that may or may not be relevant.
Organic Search is a method for entering one or a plurality of search items in a single data string into a search engine. Organic search results are listings on search engine results pages that appear because of their relevance to the search terms, as opposed to their being advertisements. In contrast, non-organic search results may include pay per click advertising.
Research - Search Engine Technology
Search is to try to locate or discover something, or try to establish the existence of something. The activity of looking thoroughly in order to find something or someone. An investigation seeking answers. The examination of alternative hypotheses.
 Hybrid Search Engine is a type of computer search engine
that uses different types of data with or without ontologies to produce
the algorithmically generated results based on web crawling. Previous
types of search engines only use text to generate their results. Hybrid
search engines use a combination of both crawler-based results and
directory results. More and more search engines these days are moving to a
hybrid-based model.
Hybrid Search Engine is a type of computer search engine
that uses different types of data with or without ontologies to produce
the algorithmically generated results based on web crawling. Previous
types of search engines only use text to generate their results. Hybrid
search engines use a combination of both crawler-based results and
directory results. More and more search engines these days are moving to a
hybrid-based model. Plant Trees while you Search the Web. Ecosia search engine has helped plant almost 18 million trees.
Question and Answers Format
Search Engine in computing is an information retrieval system designed to help find information stored on a computer system. The search results are usually presented in a list and are commonly called hits. Search engines help to minimize the time required to find information and the amount of information which must be consulted, akin to other techniques for managing information overload. The most public, visible form of a search engine is a Web search engine which searches for information on the World Wide Web.
Indirection is the ability to Reference something using a name, reference, or container instead of the value itself. The most common form of indirection is the act of manipulating a value through its memory address. For example, accessing a variable through the use of a pointer. A stored pointer that exists to provide a reference to an object by double indirection is called an indirection node. In some older computer architectures, indirect words supported a variety of more-or-less complicated addressing modes.
Probabilistic Relevance Model is a formalism of information retrieval useful to derive ranking functions used by search engines and web search engines in order to rank matching documents according to their relevance to a given search query. It makes an estimation of the probability of finding if a document dj is relevant to a query q. This model assumes that this probability of relevance depends on the query and document representations. Furthermore, it assumes that there is a portion of all documents that is preferred by the user as the answer set for query q. Such an ideal answer set is called R and should maximize the overall probability of relevance to that user. The prediction is that documents in this set R are relevant to the query, while documents not present in the set are non-relevant.
Bayesian Network is a probabilistic graphical model (a type of statistical model) that represents a set of random variables and their conditional dependencies via a directed acyclic graph (DAG). For example, a Bayesian network could represent the probabilistic relationships between diseases and symptoms. Given symptoms, the network can be used to compute the probabilities of the presence of various diseases.
Bayesian Inference is a method of statistical inference in which Bayes' theorem is used to update the probability for a hypothesis as more evidence or information becomes available. Bayesian inference is an important technique in statistics, and especially in mathematical statistics. Bayesian updating is particularly important in the dynamic analysis of a sequence of data. Bayesian inference has found application in a wide range of activities, including science, engineering, philosophy, medicine, sport, and law. In the philosophy of decision theory, Bayesian inference is closely related to subjective probability, often called "Bayesian probability".
Search Aggregator is a type of metasearch engine which gathers results from multiple search engines simultaneously, typically through RSS search results. It combines user specified search feeds (parameterized RSS feeds which return search results) to give the user the same level of control over content as a general aggregator, or a person who collects things.
Metasearch Engine or aggregator) is a search tool that uses another search engine's data to produce their own results from the Internet. Metasearch engines take input from a user and simultaneously send out queries to third party search engines for results. Sufficient data is gathered, formatted by their ranks and presented to the users.
Prospective Search is a method of searching on the Internet where the query is given first and the information for the results are then acquired. This differs from traditional, or "retrospective", search such as search engines, where the information for the results is acquired and then queried. Multitask
Subject Indexing is the act of describing or classifying a document by index terms or other symbols in order to indicate what the document is about, to summarize its content or to increase its findability. In other words, it is about identifying and describing the subject of documents. Indexes are constructed, separately, on three distinct levels: terms in a document such as a book; objects in a collection such as a library; and documents (such as books and articles) within a field of knowledge.
Search Engine Indexing collects, parses, and stores data to facilitate fast and accurate information retrieval. Index design incorporates interdisciplinary concepts from linguistics, cognitive psychology, mathematics, informatics, and computer science. An alternate name for the process in the context of search engines designed to find web pages on the Internet is web indexing.
Indexing - Amazing Numbers and Facts
Text Mining also referred to as text data mining, roughly equivalent to text analytics, refers to the process of deriving high-quality information from text. High-quality information is typically derived through the devising of patterns and trends through means such as statistical pattern learning. Text mining usually involves the process of structuring the input text (usually parsing, along with the addition of some derived linguistic features and the removal of others, and subsequent insertion into a database), deriving patterns within the structured data, and finally evaluation and interpretation of the output. 'High quality' in text mining usually refers to some combination of relevance, novelty, and interestingness. Typical text mining tasks include text categorization, text clustering, concept/entity extraction, production of granular taxonomies, sentiment analysis, document summarization, and entity relation modeling (i.e., learning relations between named entities). Text analysis involves information retrieval, lexical analysis to study word frequency distributions, pattern recognition, tagging/annotation, information extraction, data mining techniques including link and association analysis, visualization, and predictive analytics. The overarching goal is, essentially, to turn text into data for analysis, via application of natural language processing (NLP) and analytical methods. A typical application is to scan a set of documents written in a natural language and either model the document set for predictive classification purposes or populate a database or search index with the information extracted.
Social Search is a behavior of retrieving and searching on a social searching engine that mainly searches user-generated content such as news, videos and images related search queries on social media like Facebook, Twitter, Instagram and Flickr. It is an enhanced version of web search that combines traditional algorithms. The idea behind social search is that instead of a machine deciding which pages should be returned for a specific query based upon an impersonal algorithm, results that are based on the human network of the searcher might be more relevant to that specific user's needs.
Interactive Person to Person Search Engine
Gimmeyit search engine is a crowd-source-based search engine using social media content to find relevant search results rather than the traditional rank-based search engines that rely on routine cataloging and indexing of website data. The crowd-source approach scans social media sources in real-rime to find results based on current social "buzz" rather than proprietary ranking algorithms being run against indexed sites. With a crowd source approach, no websites are indexed and no storage of website metadata is maintained.
Tagasauris - Public Data
Selection-Based Search is a search engine system in which the user invokes a search query using only the mouse. A selection-based search system allows the user to search the internet for more information about any keyword or phrase contained within a document or webpage in any software application on his desktop computer using the mouse.
Web Searching Tips
Rummage is to search haphazardly through a jumble of things. Ransacking.
Web Portal is most often a specially designed web site that brings information together from diverse sources in a uniform way. Usually, each information source gets its dedicated area on the page for displaying information (a portlet); often, the user can configure which ones to display.
Networks - Social Networks
Router is a networking device that forwards data packets between computer networks. Routers perform the traffic directing functions on the Internet. A data packet is typically forwarded from one router to another through the networks that constitute the internetwork until it reaches its destination node.
Interface - Computer - Internet - Web of Life
Window to the World - Open Source
A Human Search Engine also includes. Archival Science - Archive - Knowledge Management - Library Science - Information Science.
Reflective Practice - Research - Science
Tracking - Interdiscipline - Thesaurus
Human-Based Computation is a computer science technique in which a machine performs its function by outsourcing certain steps to humans, usually as microwork. This approach uses differences in abilities and alternative costs between humans and computer agents to achieve symbiotic human-computer interaction. In traditional computation, a human employs a computer to solve a problem; a human provides a formalized problem description and an algorithm to a computer, and receives a solution to interpret. Human-based computation frequently reverses the roles; the computer asks a person or a large group of people to solve a problem, then collects, interprets, and integrates their solutions.
Internet Searching Tips
"Knowing how to ask a question and knowing how to analyze the answers"
If on a website and you're using the Firefox browser, if you right click on the page, and then click on "Save Page As", it will save the entire page on your computer so that can be view that page when you are off line, without the need of an internet connection.
When searching the internet you have to use more then one search engine in order to do a complete search. Using one search engine will narrow your findings and possibly keep you from finding what you're looking for because most search engines are not perfect and are sometimes unorganized, flawed and manipulated. This is why I'm organizing the Internet because search engines are flawed and thus cannot be fully depended on for accuracy. Adaptive Search
Example: Using the same exact keywords on 4 different search engines I found the website that I was looking for at the top in the number one position, on 2 of the 4 search engines, and I could not find that same website on the other search engine unless I searched several pages deep. So one search engine is flawed or manipulated and the other search engine is not. There are chances that the webpage you are looking for is not titled correctly so you may have to use different keywords or phrases in order to find it. But even then this is no guarantee because search engines also use other factors when calculating the results for particular words or phrases. And what all those other factors are and how they work is not exactly clear.
Search engines are in fact a highly important Social Service, just like a Congressman or President, except not corrupted of course. If you honestly can not say exactly how and why you performed a particular action, then how the hell are people supposed to believe you or understand what they need to do in order to fix your mistake or at least confirm there was no mistake? Transparency, Truth and knowing the Facts for these particular services are absolutely necessary. People have the right not to be part of a Blind Experiment. These Systems need to be Open, Monitored and Audited in order for us to work accurately and efficiently.
When searching the Internet, sometimes going several pages deep on search engines will also help find information, this is because the first 10 choices are sometimes irrelevant. I have sometimes found things that I'm looking for 30 pages deep. You will also find different key words, phrases and characters within the search results that may also help increase your odds of finding what you're looking for. Sometimes checking a websites links on their resources page may also help you find websites that are not listed correctly in search engines. Web Searching for Information needs to be a science.
Human Search Engine Tips
Most search engines like Google have Advanced Searching Tools found on the side or at the bottom of their search pages.
Knowing where to type in certain characters in your search phrases also helps you find what you're looking for.
If you want to limit your searches on Google to only education websites or government websites
then type in "site:edu" or "site:gov" after your key word or search phrase.
For example Teaching Mathematical Concepts site:edu
For searching a specific website type in "neutrino site:harvard.edu after the word or search phrase.
To narrow your searches to file types like PowerPoint, excel or pdf's then type in filetype:ppt after the word.
For search ranges use 2 periods between 2 numbers, like "Wii $200..$300."
Using quotes or a + or - within your search phrases. Example, imagine you want to find pages that have references to both President Obama and President Bush on the same page.
You could search this way: +President Obama+President Bush
Or if you want to find pages that have just President Obama and not President Bush then your search would be President Obama -President Bush.
If you are looking for sand sharks search engines will give you results with the word sand and sharks but if you use quotation marks around "sand sharks" it will help narrow your search.
Using "~" (tilde) before a search term yields results with related terms.
Regular Expression is a sequence of characters that define a search pattern. Usually this pattern is used by string searching algorithms for "find" or "find and replace" operations on strings, or for input validation. It is a technique that developed in theoretical computer science and formal language theory.
Conversions try typing "50 miles in kilometers" or 100 dollars in Canadian dollars.
Use Google to do math just enter a calculation as you would into your computer's calculator (i.e. * corresponds to multiply, / to divide, etc)
To find a time in a certain place, then type in Time: Danbury, Ct.
Just got a phone call and want to see where the call is from, then Type in 3 digit # area code.
Type any address into Google's main search bar for maps and directions.
While on Google Maps select the day of the week and the time of day for the traffic forecast.
What are people Searching for and what Key words are they using
Search Query Trends - Google Insights Search Trends - Google Trends - Google - Yahoo Alexa Web Trends
You can learn even more great search tips by visiting this website Search Engine Watch.
Learning Boolean Logic can also help with improving your Internet searching skills. Boolean Operators (youtube)
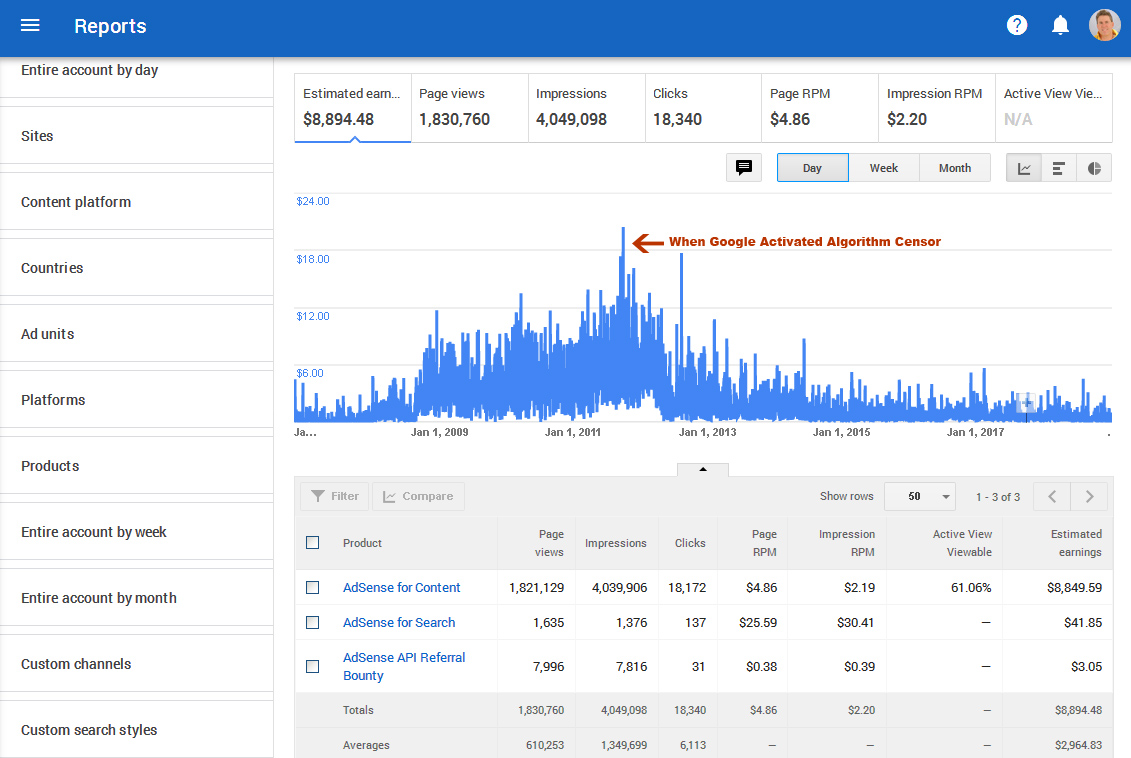
Algorithm Censorship
Google censors search results, while at the same time they killed thousands of small businesses, and not only that, they influenced other people to censor information and corrupt the system even more. Why do corporations get greedy and criminal? And why do they cause others to repeat this madness? Money and Power is a cancer in the wrong hands. So the Dragonfly censored secret search engine is nothing new. And on top of that, people are getting bombarded with robocalls because of google, and people have to visit websites littered with adds because of google, which is abusive and one of the reasons why google has been sued several times for millions of dollars. And the lawsuits are not stopping these abuses.
Problems with Google - Information Bubbles
Life through Google's Eyes, Google's instant autocomplete that automatically fills in words and phrases with search predictions and suggestions. Sometimes with disturbing results.
Google Algorithm, works OK most of the time, but it is also used to censor websites unfairly. Corruption at its worst.
 Penguin (wiki) -
EMD
(wiki)
Penguin (wiki) -
EMD
(wiki)Panda (wiki) - Google Bomb (wiki)
Criticism of Google (wiki)
Google Fined $1.7 Billion by EU for Blocking Advertising Rivals. Alphabet's Google was fined $1.7 billion by the European Union for limiting how some websites could display ads sold by its rivals.
Search Engine Failures
Algorithms - Search Algorithm
Human Search Engine
Internet - Internet Safety
"If you are indexing information, that should be your focus. If information is judged on irrelevant factors, then you will fail to correctly distribute information, which will make certain information in search results unreliable, illogical and corrupted."